When to Migrate from HPA to KEDA
Sam Farid
CTO/Founder

KEDA is now 5 years old, and we’re celebrating by sharing our top use cases and reasons to switch from traditional HPA scaling to KEDA’s much more powerful and adaptable autoscaling platform.
Scale Proactively on Real Traffic Load
For many types of applications, traditional CPU and Memory utilization metrics are an indirect measure of incoming requests and do not directly measure true demand:
- For queue consumers, utilization is a lagging indicator and the queue can get backed up before scaling occurs.
- For web applications, utilization may not even correlate with the request load since it depends on what actions the user is taking.
- For batch processing jobs, utilization is highly variable depending on timing and size of data batches, so pods can quickly get overwhelmed.
With KEDA’s event-driven scaling, applications can proactively scale on incoming traffic, using native support for event sources such as Kafka or SQS. Scaling directly on queue length has clear benefits:
- This will not only clear the queue faster, but also has positive downstream effects: if you’re using spot nodes (e.g. Karpenter), then it gives the node scheduler more advance notice and avoids potential cold starts.
- Applications with high variability and strict latency requirements will be able to shapeshift to all types of incoming traffic.
- During scale down, resources will be cleared faster, similarly avoiding lagging over-provisioning and therefore saving money.
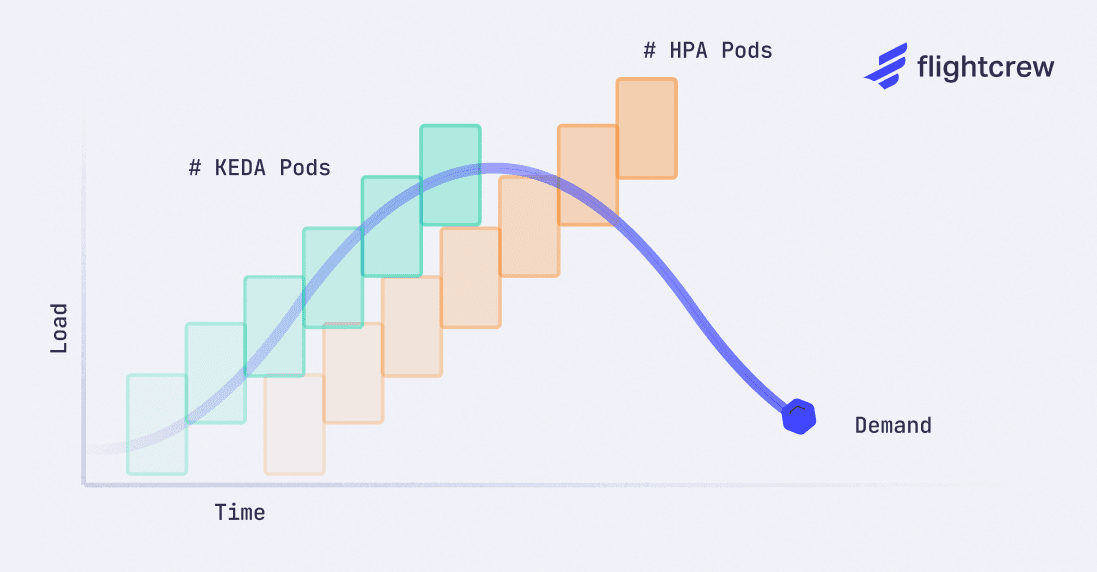
KEDA is able to proactively scale on events to match the incoming demand. Although HPA supports some custom metrics, it has fewer controls and relies on polling, resulting in lagging reactions and over-provisioning for the traffic spike.
Coordinate Scaling to Avoid Cascades
When interdependent microservices scale with HPAs, it’s difficult to avoid bottlenecks from cascading. Increased traffic to a web application will cause it to scale up first before its downstream auth service knows that a big wave is coming in. Since each independent HPA scales on its own interval, the downstream scaling lag is worse for the second hop, and the performance issues can continue to snowball from there.
KEDA allows for shared triggers across multiple microservices, enabling them to scale in tandem. Just use the same custom metric scaling definition for each one.
- Not only is this unified scaling more proactive, it’s also easier to manage and debug when there’s just one scaling policy operating on many microservices, rather than having to chase down individual HPA logic.
Avoid Wasted Spend on Cronjobs for Data & AI Applications
For data batch jobs such as model retraining or backfills, a common setup is to run a “wake and check” cronjob that triggers on a schedule, polls the current state, and maybe does some work or maybe shuts off. It's quite wasteful to provision a container to run (perhaps even on GPUs) when nothing needs to be done. And even worse, the regular schedule can mean that anything urgent happening in between runs will need to wait till the next cron trigger to resolve.
Unlike HPA, KEDA allows scaling to zero, so these periodic jobs can be transformed into event-driven triggers. They’ll stay dormant, scale from 0 to 1 (or more) on a trigger, and then disappear when there’s no more work to do.
For example, AI retraining jobs can trigger on a live measure of model validation, ensuring that precious GPUs are only spent when there’s significant drift.
- This is an improvement on correctness by ensuring retraining happens right on time, while also being an efficiency gain to avoid fully provisioning pods when they’re unnecessary.
- And a nice bonus: application code is simpler when its trigger logic is factored out into KEDA configs.
Scaling can be controlled by a simple gauge in Prometheus, allowing other applications to trigger both the wakeup call and even the “go back to sleep” call:
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: retrain
spec:
jobTargetRef:
template:
spec:
containers:
- name: retrain-worker
image: retrain-image-0123
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server
metricName: validation_miss
threshold: '1'
KEDA’s scaling modifiers allow for much finer-grain controls for AI jobs to achieve further efficiency gains, read more here: https://www.flightcrew.io/blog/keda-scaling-modifiers
Go Serverless
We all know the pros and cons of fully-managed Serverless platforms like AWS Lambda and GCP Cloud Run. But the downsides provide a tough series of tradeoffs:
- You want to save costs by scaling to zero, without the cold start performance penalties.
- You want seamless and config-less autoscaling, without having to debug random instance count spikes and drops.
- You want stateless workloads to be taken care of, without needing to set up a bunch of other stateful infrastructure to support it.
KEDA’s HTTP add-on can buffer incoming requests and trigger scaling based on the demand, passing along requests after scaling up. This has numerous benefits over the alternative:
- This creates serverless-like functionality for containers, which can even be used on individual workloads within the cluster, allowing for a hybrid approach for maximum flexibility and cost efficiency.
- The install and setup is easy, with low maintenance overhead and high flexibility.
- A caveat is that it has some known scaling challenges at high throughput, so may not be ready yet to stand alone in the big leagues, but continues to be developed every day.
Scale Every Workload with KEDA
Transitioning from HPA to KEDA unlocks an autoscaling platform for every type of workload. By enabling event-driven triggers, scaling directly on workload demands, and scaling down to zero, you can achieve more responsive and cost-effective applications.
Flightcrew makes it easier to set up and maintain autoscalers for every scenario. If you’re interested in using Flightcrew to get started with KEDA, send us a note at hello@flightcrew.io.
Sam Farid
CTO/Founder
Before founding Flightcrew, Sam was a tech lead at Google, ensuring the integrity of YouTube viewcount and then advancing network throughput and isolation at Google Cloud Serverless. A Dartmouth College graduate, he began his career at Index (acquired by Stripe), where he wrote foundational infrastructure code that still powers Stripe servers. Find him on Bluesky or holosam.dev.



